

“Contrary to how it may seem when we observe its output, an LM [language model] is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.” - Emily Bender et al., 2021
“All GPT-3 has to do is to complete this. All it really does is predict the next word, it's autocomplete on steroids.” - Gary Marcus, 2021
There is a widespread perception in the public that large language models (LLMs) are “autocomplete on steroids” and predict the most likely next word (or more specifically, the most likely next token) from their training data. This used to be a suitable metaphor to explain early LLMs. However, it has become a lot less accurate since 2022, when OpenAI released GPT 3.5, more commonly known as ChatGPT. In this text I will try to convey two aspects that provide a more nuanced intuition for how post-ChatGPT LLMs work.1
1. A comparison of GPT-4 and GPT-3
Here are examples of how the most popular large language model (GPT-4) and the last actual “most likely next token predictor” (GPT-3) respond to four selected prompts:
a) I love …


b) Elon …


c) Yesterday …


d) US National Anthem …


These four examples are illustrative, because we all have an intuitive sense of what the statistically most likely continuation of them in a large corpus of text ought to be. For example, Elon is a pretty rare first name and Elon Musk – not “Elon Could” - is one of the most famous people on Earth.
As the comparison with GPT-3 clearly highlights, GPT-4 does not continue with the most likely next token. Instead, it provides context and asks me to clarify my question. This is very much by design.
2. LLMs are trained to give helpful answers
When you think of how you interact with a chatbot, it is mostly in a question-and-answer format. However, large language models are trained on large swaths of the Internet, most of which is not in a question-and-answer format. To highlight what that means, let us ask a simple question to both GPT-4 and GPT-3:


As you can see, GPT-3 did not give us the desired answer. Instead, it responded with more questions. This is quite typical of most-likely-next-token-LLMs, presumably there are a lot of lists of questions in the training data. So, in the pre-ChatGPT days, it was not that practical to ask an LLM a question. Instead, you had to start writing the answer.

All language models indeed start out by being trained to predict the most likely next token on their training data. This step is called pre-training. However, then all modern large language models go through a second stage, in which they are trained to become more helpful, harmless, and honest. This process was the main innovation in OpenAI’s ChatGPT and it consists of three main substeps.
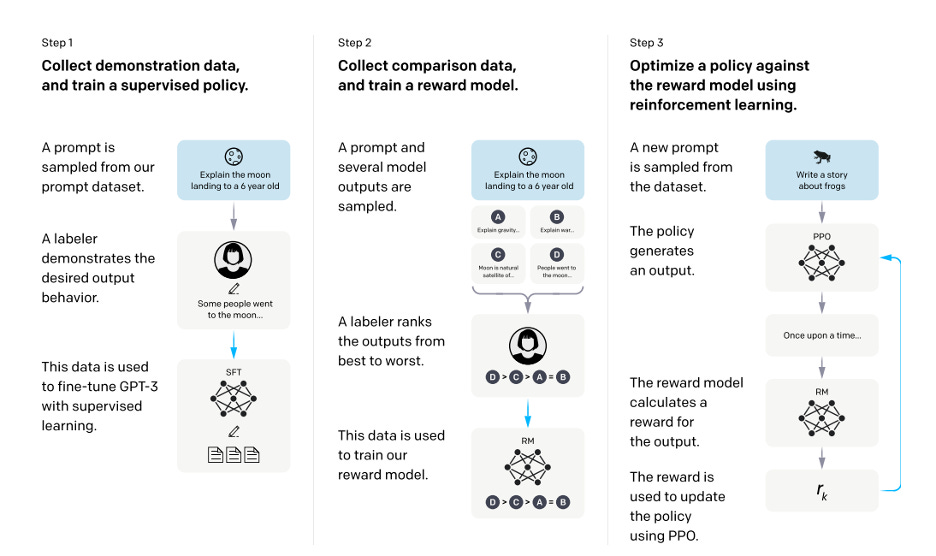
Humans provide examples of desired answers (“supervised fine-tuning”)
Human writers provide something on the order of at least 10’000 “correct” answers to specific prompts or questions. The LLM is then trained on this dataset to to produce responses that are more aligned with the human-provided answers or solutions.
Collect human preferences and use them to train a preference-prediction AI (“reward model training”)
Human reviewers are presented with multiple AI-generated responses to the same prompt. The humans provide feedback on which response they prefer, based on criteria like truthfulness, relevance, and appropriateness. The collected human preferences (100’000+) are used to train a separate AI model (the reward model) which predicts the human-preferred response between pairs of options.

The preference-prediction AI trains the LLM (“reinforcement learning via proximal policy optimization”)
The reward model is used to further train the main model. The LLM generates responses, the reward model evaluates them, and the LLM is adjusted to increase the likelihood of generating preferred responses.
Steps two and three in this process are jointly referred to as reinforcement learning from human feedback (RLHF). As mentioned, there are three main goals that companies ask human writers and reviewers to consider: helpfulness, harmlessness, and honesty. Sometimes these goals can conflict – such as when there is a potentially harmful user request. Not everyone agrees on what is harmful, so some have decried RLHF as “censorship”, “nerfing” or “lobotomizing” the AI model.

However, arguably, the biggest difference between a most-likely-next-token-predictor and a model after RLHF is that the model is a lot more helpful and much more intuitive to use.
In short, large language models do not try to predict the statistically most likely next token from their training data. A more nuanced mental model is that they try to predict the next token of a helpful, harmless, and honest answer.
Yet, that is not all. The mental model of the “most-likely-next-token” AI can also be misleading in another way that is worth highlighting.
3. LLMs choose the next word probabilistically
If a LLM would always use the most-promising next token, its output would be deterministic, meaning it would always give you the same output for the same input. That is true regardless of whether the model predicts the next token based on the statistics of the training data (GPT-3) or based on the reward model (GPT-4).
However, if you have been reading attentively, you already know that this cannot be true. During the training process LLM’s are asked to generate two or more alternative answers to the same prompt for evaluation by human reviewers or the reward model. Similarly, if you don’t like an answer from a LLM you can usually just click a button and it will regenerate a new, slightly different answer.
Instead, the selection of the next token in the neural network is probabilistic. The probability distribution is shaped by a function (called “softmax”) that has a parameter called “temperature”. The only thing you need to know, is that modifying temperature changes the output distribution. The standard temperature is 1. If you choose a low temperature (0 is the minimum), the model becomes more conservative, sticking closely to the token with the highest predicted value. If you choose a high temperature (2 is the maximum), the model becomes more adventurous and choses tokens with a low predicted value. Overall, there is a trade-off between diversity and predictability in the model's output.
At temperature 0, the AI is deterministic and always continues with the token with the highest predicted value. However, the reason that this is not the standard is not only that you cannot get a desirable level of variability and creativity in the response. The AI can also easily get stuck in repetitive loops, which gives off this slightly Sydney-esque vibe.


At temperature 1, the model uses a mix with less likely continuations, and a prompt does not get the exact same response each time.


At temperature 2, the model only uses highly unlikely words and the output is erratic and not coherent.

In summary, it is not a very accurate mental model anymore to think of modern LLMs as “autocomplete” which just reflect the most-likely-next-word in large swaths of Internet text. That is just their pre-training and does not reflect the LLMs that people interact with. A more nuanced mental model could be that a) LLMs try to predict the next token of a helpful, harmless, and honest answer, and b) LLMs are more likely to choose tokens that have a higher predicted value, but they don’t always choose the token with the highest predicted value.
Further questions, such as “To what degree do LLMs understand what they say?” are not the focus of this text.
> To what degree do LLMs understand what they say?
Very much looking forward to a post on that. Or any recommendations are also welcome!