

“The vast bulk of the AI field today is concerned with what might be called “narrow AI” – creating programs that demonstrate intelligence in one or another specialized area (…) The AI projects discussed in this book (…) are explicitly aimed at artificial general intelligence, at the construction of a software program that can solve a variety of complex problems in a variety of different domains” – Ben Goertzel & Cassio Pennachin, 20071
Lex Fridman: “So, OpenAI and DeepMind was a small collection of folks who were brave enough to talk about AGI in the face of mockery.” Sam Altman: “We don't get mocked as much now.” - Lex Fridman Podcast, 2023
“I liked the term AGI 10 years ago, because no one was talking about the ability to do general intelligence 10 years ago and so it felt like a useful concept. But now I actually think, ironically, because we're much closer to the kinds of things AGI is pointing at, it's sort of no longer a useful term. It's a little bit like if you see some object off in the distance on the horizon you can point at it and give it a name, but you get close to it (…) it's kind of all around you (…) and it actually turns out to denote things that are quite different from one another.” – Dario Amodei, 2023
Artificial general intelligence or short “AGI” is the hottest term in Silicon Valley. Building AGI is not science-fiction anymore. It is the declared goal of nearly all the world’s largest tech companies from Microsoft and OpenAI, to Alphabet and Google Deepmind, to Amazon, to Facebook. It is a goal backed by many billions of dollars of long-term investments. But what exactly does AGI mean?
As always, the devil lies in the details. This text provides an overview of AGI tests and definitions, and highlights some of their differences and challenges. Specifically:
AGI ≠ AGI: There are wildly different definitions of AGI, which makes the popular sport of predicting a specific date for AGI a confusing affair. Some experts say we already have AGI, others predict AGI by 2027, others by 2031, others by 2047, and in principle they could all be right.
Some AGI definitions are highly asymmetric: AGI is sometimes equated with “human-level AI”, but the most cited survey on AI timelines uses a definition of AGI that requires much more from AI systems than from humans. Applying the same logic to humans and dogs, humans would not qualify as dog-level intelligence.
Current frontier LLMs can reasonably be thought of as AGIs: The emphasis in the term AGI is on generality, and LLMs have a broader spectrum of decent performance on cognitive tasks than any individual human.
We need terminology beyond the narrow-general dichotomy: There will never be an unambiguous agreement on what qualified as the first AGI system. Furthermore, the label AGI can apply to a broad range of systems. To have a productive discourse, it makes to make more fine-grained distinctions about the range, performance, autonomy, and risk levels of frontier AI systems.
Current frontier LLMs have a lot of crystallized intelligence, but they arguably don’t have human-level fluid intelligence yet: The distinction between accumulated knowledge, skills, and vocabulary (crystallized intelligence) and abstract reasoning and problem solving in novel situations (fluid intelligence) is well-established for human general intelligence and it may also help to make sense of divergent intuitions about AI performance and trajectories.
1. AGI definitions and tests
Building machines with general intelligence was the goal of the field of AI at its inception in the 1950s, and this is reflected in attempts such as Herbert Simon and Allen Newell’s General Problem Solver and Soar. However, as early overconfidence waned in the 1970s, researchers began to focus almost exclusively on machine intelligence in narrow domains.
The term “artificial general intelligence” became popular2 as the title of a 2007 book, that brought together researchers interested in building AI with general intelligence, as opposed to the prevalent focus on AI applications in narrow domains. The term AGI was also chosen as a more method-neutral alternative to the term human-level AI.3 The two largest and most prominent efforts to build AGI have been Deepmind (founded 2010, acquired by Google 2014) and OpenAI (founded in 2015). However, since the dramatic success of ChatGPT in late 2022 most major tech companies have also adopted AGI as their goal.
The following list of 20 AGI tests and definitions is not intended to be comprehensive. However, it provides a sufficient overview to navigate the AGI discourse. It includes well-specified AGI tests and the most important AGI definitions.
As a mental shorthand, I think it makes sense to think of AGI tests and definitions in three main clusters:
Language-related tests: Language is open-ended and good performance on open-ended interrogation is indicative of a broad knowledge of concepts and relations. The archetypal language test is the Turing Test. Further language-related tests focus on linguistic complexity, linguistic creativity, text compression, and reading comprehension. CAPTCHAs and University exams are also often heavy on language-related tasks. Language used to be one of the grand challenges of AI but with the advent of large language models, AI can essentially pass all language-related AGI tests.
Physical manipulation tests: A second set of tests do not focus solely on cognitive tasks, but on manipulating objects in the real world. The archetypal test is the Total Turing Test, more narrow versions of this are the coffee test, working as a cook in an arbitrary kitchen, assembling IKEA furniture or assembling a toy automobile. Physical manipulation requires a range of sensors and actuators as well as cognitive skills (e.g., vision, movement in complex environments, endurance, tactile sensitivity, dexterity, auditory processing) and it is arguably also more resource-intensive, and safety-critical than purely cognitive tasks. AGI tests for general-purpose robotics have not been passed yet.
Economically valuable work: A third set of AGI definitions focus on economic impact. The archetypal representation of this cluster is Nilsson’s employment test. Similar approaches have been taken by Nick Bostrom, Katja Grace et al., OpenAI, Ajeya Cotra, and Mustafa Suleyman.4 On the one hand, focusing on economic impact has the advantage of strong validation of significance in the real world. On the other hand, economic impact of general-purpose technologies is naturally a lagging indicator and attribution of automation and economic growth to a single technology may not always be easy. AGI definitions and tests focusing on economic impact have not been passed yet.
2. Discussion
In this section, we will discuss four points that are worth considering in the discourse around AGI. Why some AGI definitions are highly asymmetric, why frontier AI can already be reasonably called AGI, why we need to beyond the dichotomy between narrow and general AI, and what we can learn from human general intelligence.
2.1 Some AGI definitions are highly asymmetric
AGI is sometimes used synonymously with “human-level AI” and implicitly many seem to think that AI is inferior to human intelligence until a specific AGI definition or test is passed. This is wrong. Several of the most popular AGI tests and definitions are highly asymmetric and put a much higher burden on the assessed type of intelligence (AI) than on the reference category intelligence (human). Hence, some of the more demanding definitions of AGI will likely only be achieved substantially *after* humanity has likely already lost control over the economy and politics. To phrase it more prosaically, if tests for AGI are supposed to be some kind of fire alarm to prepare a response for imminent economic impact or catastrophic risks, it doesn’t seem wise for them to require the entire building having burnt down before going off.
The fundamental asymmetry in these definitions or tests is that they are open-ended and to pass them, they require AI to perform at least as well as an average human, a professionally specialized human, or even the best professionally specialized human on all tasks. In other words, what is counted is not some weighted sum of performance over a large range of tasks. Instead, we only count the relatively weakest AI performance and the relatively strongest human performance.
Here are two simple ways to visualize this: a) a spider graph with performance on a few dimensions, b) Moravec’s metaphor of the landscape of human competences with AI as a rising tide. In this metaphorical landscape, the valleys are areas of more moderate human performance, and the peaks represents the most complex human abilities, whereas the rising ocean represents AI capabilities.


Turing Test: The test is open-ended, so if humans are reliably better than AI in 1 out of 1000 cognitive skills or types of knowledge the evaluator can purposefully steer the conversation towards those. This means that especially in its adversarial form with an expert that specifically hunts for weak spots in the AI, this is highly asymmetrical. Just consider an inverse Turing test in which humans would have to fool human or machine judges into believing that they are an AI. Humans would have arguably failed such a test reliably for at least 60 years or so due to machine superiority in simple mathematical calculations (what’s 231 * 398 again?). In fact, the existing machine superiority in many areas makes the traditional Turing Test more complicated to pass for AI systems. In these tasks, the AI must pretend to be as slow and clueless as a human, to not be detected due to superiority. The Turing Test does not measure equality between humans and AI, in its more strict, adversarial interpretation, the test measures when humans have lost their last linguistically representable cognitive advantage over AI.
The last human job: The most widely cited publication on AGI timelines is the AI expert survey from Katja Grace et al. (2017) with follow-ups with the same methodology in 2022 and 2024. The survey asks AI researchers to guess by what year “high-level machine intelligence”, defined as “when unaided machines can accomplish every task better and more cheaply than human workers” exists. The author’s state: “Our goal in defining ‘high-level machine intelligence’ (HLMI) was to capture the widely discussed notions of ‘human-level AI’ or ‘general AI’”. This is also how the survey has been communicated to a broader audience (OurWorldInData, WEF).
However, this definition puts an extremely high bar for AGI. To highlight the asymmetry, let’s consider, what happens if we apply the same definition to humans with dogs as reference category:
Humans have more intelligence than dogs: An individual human has about 150 times more neurons than a dog, and humans as a culture-driven species have a vastly superior collective intelligence to dogs in nearly all aspects: Humans have complex spoken and written language. Humans have built megacities, satellites, atomic bombs, and telecommunication. Humans are even superior at many wolf or dog-specific tasks, such as hunting large mammals such as deer, elk, bison, and moose, or treating injured or sick dogs.
Humans have control over dogs: Humans control the genetic evolution of dogs from wolves to fluffy handbag dogs. Humans largely control dog reproduction. Humans control dog education. Humans choose and produce the food that dogs get to eat. Humans also choose and provide the dog housing. Humans buy and sell dogs. Humans limit the free movement of most dogs to controlled excursions on a leash.
Applying the “Grace et al.” definition of AGI to dogs & humans, humans would NOT qualify as dog-level intelligence, let alone as superdog intelligence: Dogs are not just part of the human economy as companions and entertainment. Specialized dogs still outperform alternatives in price-performance in niche tasks in the human economy5 ranging from search and rescue (e.g., missing people, avalanches), to law enforcement and military (e.g., drug and explosives detection, apprehension of fleeing suspects), to social assistance (e.g., guide dogs for the blind, therapy dogs), to transport (e.g., sled dogs), to agriculture (e.g., herding dogs), to hunting (e.g., fox hunt).
In short, if we take the phrasing of the survey seriously6, it puts the bar for AGI not when AI represents a significant share or the majority of Earth’s economy, but more or less when the last human transitions out of the economy. The definition used by Vincent Müller & Nick Bostrom in their survey as “one that can carry out most human professions at least as well as a typical human” is more lenient but still a very high threshold.
Most jobs entail a set of tasks. What if AI is faster and qualitatively better at 95% of original tasks for a job but requires human help for the last 5%? Well, the human profession now consists of those remaining tasks.
Human jobs are a moving target too. Once a job such as ice cutter, streetlamp lighter, or barge hauler has been fully automated, does it still count as a “human profession”?
Again, let’s use dogs and humans as a sanity check. Can a human carry out most dog professions at least as well as a typical dog? The answer largely depends on how you conceptualize dog professions and a typical dog, it is not an unambiguous yes. The OpenAI definition of “highly autonomous systems that outperform humans at most economically valuable work” is still a lagging indicator, but at least it is worded in a way that avoids the strongest asymmetries.
2.2 Frontier LLMs already have a broad range
As discussed, AGI is an ambiguously defined concept and, in some definitions, there is an extremely high bar for AGI. As such, there is not one correct answer as to whether current frontier AI qualifies as AGI. This is socially constructed and very much depends on the definition. Having said that, I personally agree with Blaise Agüera y Arcas and Peter Norvig, who make the case that current frontier AIs can be thought of as AGI. They highlight five factors that support this interpretation:
Range of topics: Frontier models are trained on hundreds of gigabytes of text from a wide variety of internet sources, covering any topic that has been written about online.
Range of tasks: Frontier models can answer questions, generate stories, summarize, transcribe, translate, explain, make decisions, do customer support, call out to other services to take actions, etc.
Range of input and output modalities: The most popular models operate on images and text, but some systems also process audio and video, and some are connected to robotic sensors and actuators.
Range of languages: English is over-represented in the training data of most systems, but large models can converse in dozens of languages and translate between them, even for language pairs that have no example translations in the training data
Ability to learn: Frontier models are capable of “in-context learning,” where they learn from a prompt rather than from the training data. In “few-shot learning,” a new task is demonstrated with several example input/output pairs, and the system then gives outputs for novel inputs.
Some may want to avoid the term AGI because they associate it with economic transformation, capabilities, and risks that have not materialized yet. However, the inherent emphasis in the term AGI is on generality, not on a specific level of capability or autonomy. Further, the origin of the term AGI is also specifically as part of a dichotomy with narrow AI. Asked differently: Can anyone seriously make the argument that frontier LLMs still fit the label “narrow AI” just because they have no control over actuators in the real world (yet)?
In the words of Geoffrey Hinton: “Things like ChatGPT know thousands of times more than any human, in just sort of basic common-sense knowledge”. The reality is that LLMs do not just have general knowledge, they have “supergeneral knowledge”, broader than any human. Measured by the correlation of the levels of knowledge on different subjects as well as the range of subjects with decent knowledge, I am the narrow intelligence with my peaks of expertise and ChatGPT is the generalist with a vast and fairly even ocean of knowledge.
2.3 We need terminology beyond the narrow-general dichotomy
In 2024, a group of technical and policy researchers from Google Deepmind have published a categorization that distinguishes between different levels of AGI. This group notably includes Shane Legg, the co-founder of Deepmind, who coined the term Artificial General Intelligence, and has arguably spent more time thinking about intelligence definitions than any other AI scientist or tech CEO. So, this is the authoritative view from Google Deepmind.
This not the main point of the paper, but it’s still worth highlighting that the authors acknowledge that OpenAI’s ChatGPT, Facebook’s Llama, and Google’s Bard/Gemini all qualify as AGI.
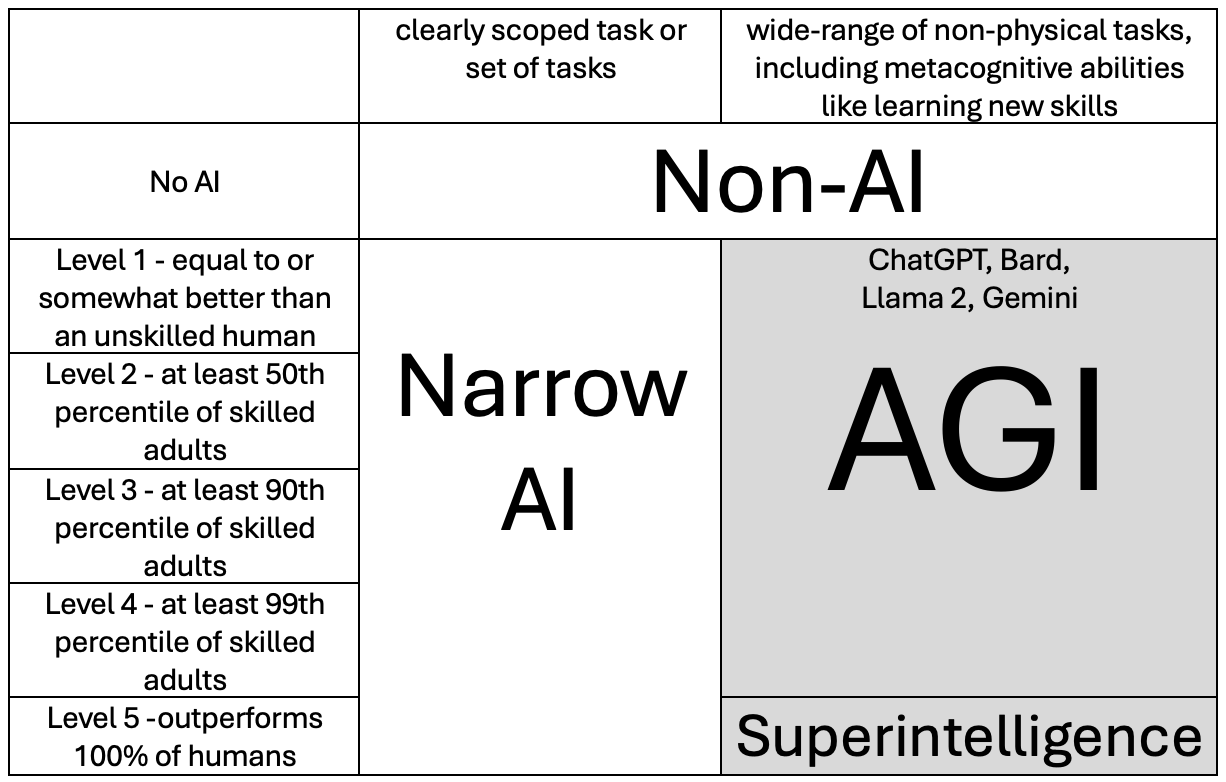
Overview graph, edited by the author for clarity, from Morris et al. (2024). Levels of AGI: Operationalizing Progress on the Path to AGI. arxiv.org p.6 AGI is still an extremely broad category, and we need more fine-grained distinctions to sensibly talk to each other. While the authors use the term AGI for all systems that have a wide range and at least unskilled human performance, they introduce distinct levels of AGI based on performance. So, current frontier LLMs are AGI but only “Level 1 – Emerging AGI”. Other AGI definitions would require performance at levels 2, 3, 4, or 5.
The authors offer no similar granularity for generality. Maybe this is not needed since today’s systems already have a very broad range. Still, there will be even more general systems in the future and there are those who insist on physical manipulation as part of AGI. So, one might consider a similar distinction for generality as for performance (e.g., Level 4 – at least 99 percent of professional tasks) or to at least have an additional qualifier: “Total AGI” refers to systems that perform well on the Total Turing Test and that have a wide-range of both physical and non-physical tasks. So, “Total Emerging AGI” would perform equal to or somewhat better than an unskilled human at a wide-range of physical and non-physical tasks.
Having more gradual and well-defined terms that an umbrella term such as AGI is also useful for autonomy and safety. The Deepmind authors also introduce levels of AI autonomy. Anthropic has introduced AI safety levels. Both are useful concepts to not get stuck in the present or wildly diverging ideas of what AGI is and to focus the conversation on what frontier AI systems already can do, what they are projected to be able to do in 2, 5, 10, 50, or 100 years, and what policies and social responses are required to mitigate their risks.

2.4 Frontier LLMs have a lot of crystallized intelligence, but they arguably don’t have human-level fluid intelligence yet
Speaking of AGI categorizations. The main subdivision of human general intelligence into crystallized and fluid intelligence may also be useful for thinking about AGI. A more comprehensive discussion of similarities and differences between the human brain and AI can be found separately.
2.4.1 Crystallized vs fluid intelligence in humans
The notion of general intelligence in humans was introduced by Spearman in 1904. He observed and defined this “g-factor” as the positive statistical correlation between the performance on tests on different subjects. For example, a student who gets good grades in French (linguistic) is more likely also get good grades in Mathematics (logical-mathematical). Human general intelligence is often subdivided further into fluid and crystallized general intelligence.
Fluid intelligence: The capacity to reason and solve novel problems, independent of knowledge from the past. It involves the ability to:
Think logically and solve problems in novel situations.
Identify patterns and relationships among stimuli.
Learn new things quickly and adapt to new situations.
Fluid general intelligence correlates with white matter volume and integrity and typically peaks around age 20. Working memory capacity is closely related to fluid intelligence, and has been proposed to account for individual differences.
Crystallized intelligence: The ability to use accumulated skills, knowledge, and experience. It largely relies on accessing long-term memory.
Vocabulary and comprehension of complex texts.
Accumulated skills from years of practice in specific areas.
Accumulated knowledge of historical facts or scientific concepts
Crystallized intelligence grows throughout life as individuals learn and experience more, and remains stable or even increases with age, typically beginning to decline around age 65. While crystallized intelligence is arguably more specialized than fluid intelligence it does include a lot of broad knowledge such as cultural literacy, vocabulary, and knowledge for everyday tasks.

2.4.2 Crystallized vs. fluid intelligence in AGI
The distinction between crystallized and fluid intelligence may be useful for AGI because it gets at something that performance on most tests cannot measure well. AI may get a good performance on most tests by memorizing and “guessing the teacher’s password” without having it embedded in a world model. In contrast, if it gets the same performance on the same tests through logic reasoning this is much more impressive.
If we just have crystallized AGI without fluid AGI, this can still be very transformative. However, reliability will always have some limitations and it will be difficult to ever get fully rid of hallucinations. In contrast, if we have fluid AGI we can have more trust in the reliability of its outputs. However, human-level fluid AGI also makes it much more likely that an intelligence explosion that leaves humanity in the dust in a short period of time will happen.
Crystallized AGI: AI can soak up much more data than any human brain. So, in data-rich domains AIs already have a humanity-level generality of accumulated knowledge. Again, is there any human that can fluently speak all major natural languages, pass coding interviews in all major programming languages, get master’s degrees in more than dozen different subjects, pass the bar exam, create recipes, and perform in poetry and rap battles?
High-performing humans still have narrow advantages on knowledge questions in their fields of expertise and humans still have an advantage over digital intelligence when it comes to manipulating things in the physical world.
Fluid AGI: Interacting with ChatGPT feels like interacting with a smart human. However, from time to time it makes mistakes of a nature that you would most certainly not expect from a smart human, and that in turn makes you question how much of the AIs smartness is the memorization of ungodly amounts of data and how much of it is actual reasoning. Given that AI is largely a black box this remains an open debate. My sense is that there is currently some level of reasoning but no human-level reasoning.
There are different types of human intelligence tests, but the most common ones, such as Raven's Progressive Matrices and the Cattell Culture Fair Intelligence Test (CFIT), aim to assess fluid general intelligence rather than cultural or domain-specific knowledge and skills. I have tested GPT-4o on the most popular test of human fluid general intelligence: Raven’s Progressive Matrices, using screenshots from an online test. The test consists of 5 * 12 matrices of progressive difficulty (A=easiest, E=hardest). The results were quite conclusive.
In the A-series, ChatGPT got 7 out of 12 answers right, after that it did not perform better than guessing by chance. The test was not entirely kind with GPT-4o and called it mentally retarded.7

Close but no cigar. Example of a mistake GPT-4o made in the A-series.

Now, there’s a bunch of arguments why GPT-4o’s true fluid intelligence performance might be better or worse than the test results that I got.
Worse: It’s quite likely that some of these questions were contained together with answers somewhere in the vast seas of the training dataset (for instance, if SciHub is the training dataset, there’s tons of papers talking about Raven’s Progressive Matrices, or I’m sure people have talked about this in some remote corners of Reddit, Twitter, or Wikipedia).
Better: Maxim Lott has reported better results giving frontier AIs the blind version of the test, which is entirely text-based (ChatGPT = 85 IQ). Similarly, Taylor Webb et al. have replaced visual pattern recognition with digit matrices and reported that GPT-3 can beat the average human in these. The potential argument here could be that the main reasoning in GPT-4o is linguistic in nature and that the translation from visual to verbal is currently the weakest link. I also didn’t bother trying to use chain-of-thought prompting etc.
Still, the gist of it is that ChatGPT has a vastly superhuman generality of accumulated knowledge, but its current fluid intelligence is arguably still below the level of most adult humans.
2.4.3 Crystallized-fluid matrix
Personally, I also find a graph with fluid intelligence and crystallized intelligence a simple but useful way to visualize archetypal future AI scenarios:

Great Data Wall: The “Great Data Wall” represents the fact that we will soon run out of available data from humans to train AI. If AI can only learn from imitating humans, then AI will soon plateau until there is some conceptual breakthrough. Archetypal proponent: Gary Marcus.
Smooth Scaling: The “Smooth Scaling” or slow take-off scenario reflects a continuous and incremental growth in fluid intelligence, presumably enabled by substituting human data with more compute and more synthetic data. Archetypal proponent: Sam Altman.
Intelligence Explosion: The “Intelligence Explosion” or fast take-off scenario assumes that AI will be able to iteratively improve itself in fast feedback loops and become vastly superhuman in a relatively short period of time. Archetypal proponent: Eliezer Yudkowsky.
Goertzel, B., Pennachin, C. (2007). Artificial General Intelligence. Springer.
There was an isolated previous use by Mark Gubrud in 1997 and there were various AI researchers that talked about “general intelligence” as a goal for AI without using the exact term “artificial general intelligence”
Goertzel, B., Pennachin, C. (2007). Artificial General Intelligence. Cognitive Technologies. Springer. p. VI / The analogy to human general intelligence is obviously still there, although, somewhat ironically, Goertzel and Pennachin argue that humans have no general intelligence. Pennachin, C., Goertzel, B. (2007). Contemporary Approaches to Artificial General Intelligence. In: Goertzel, B., Pennachin, C. (eds) Artificial General Intelligence. Springer. pp. 6&7
Mustafa Suleyman. (2023). The Coming Wave: Technology, Power, and the Twenty-first Century's Greatest Dilemma. Crown. p. 100
This is different from dog actors, dog beauty contests or dog races, where being a dog is an essential characteristic.
Which survey respondents may not necessarily do.
The respondent age was set to 25, to get the results for adults.
Great overview and argumentation, this solves a framing problem I hadn't yet had time to think about. Really valuable reference. Proud that this was published from our office space!
Thanks for this writeup and resource, really useful and I'll be drawing on this for a book project. In case of interest, last year I did an adjacent review of this and various other terms that have been coined in debates around advanced AI (though less in-depth in its discussion of AGI specifically), at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4612473